Example: Bayesian quantification of parameter uncertainty:
Estimating the (Gaussian) posterior pdf of the coefficient parameter field in an elliptic PDE
In this example we tackle the problem of quantifying the uncertainty in the solution of an inverse problem governed by an elliptic PDE via the Bayesian inference framework. Hence, we state the inverse problem as a problem of statistical inference over the space of uncertain parameters, which are to be inferred from data and a physical model. The resulting solution to the statistical inverse problem is a posterior distribution that assigns to any candidate set of parameter fields our belief (expressed as a probability) that a member of this candidate set is the ``true'' parameter field that gave rise to the observed data.
For simplicity, in what follows we give finite-dimensional expressions (i.e., after discretization of the parameter space) for the Bayesian formulation of the inverse problem.
Bayes' Theorem:
The posterior probability distribution combines the prior pdf over the parameter space, which encodes any knowledge or assumptions about the parameter space that we may wish to impose before the data are considered, with a likelihood pdf , which explicitly represents the probability that a given set of parameters might give rise to the observed data , namely:
Note that infinite-dimensional analog of Bayes' formula requires the use Radon-Nikodym derivatives instead of probability density functions.
Gaussian prior and noise:
The prior:
We consider a Gaussian prior with mean and covariance . The covariance is given by the discretization of the inverse of differential operator , where , control the correlation length and the variance of the prior operator. This choice of prior ensures that it is a trace-class operator, guaranteeing bounded pointwise variance and a well-posed infinite-dimensional Bayesian inverse problem
The likelihood:
Here is the parameter-to-observable map that takes a parameter vector and maps it to the space observation vector .
The posterior:
The Gaussian approximation of the posterior:
The mean of this posterior distribution, , is the parameter vector maximizing the posterior, and is known as the maximum a posteriori (MAP) point. It can be found by minimizing the negative log of the posterior, which amounts to solving a deterministic inverse problem) with appropriately weighted norms,
The posterior covariance matrix is then given by the inverse of the Hessian matrix of at , namely
The prior-preconditioned Hessian of the data misfit:
The generalized eigenvalue problem:
where contains the generalized eigenvalues and the columns of the generalized eigenvectors such that .
Randomized eigensolvers to construct the approximate spectral decomposition:
When the generalized eigenvalues decay rapidly, we can extract a low-rank approximation of by retaining only the largest eigenvalues and corresponding eigenvectors,
Here, contains only the generalized eigenvectors of that correspond to the largest eigenvalues, which are assembled into the diagonal matrix .
The approximate posterior covariance::
Using the Sherman–Morrison–Woodbury formula, we write
where . The last term in this expression captures the error due to truncation in terms of the discarded eigenvalues; this provides a criterion for truncating the spectrum, namely that is chosen such that is small relative to 1.
Therefore we can approximate the posterior covariance as
Drawing samples from a Gaussian distribution with covariance
Let be a sample for the prior distribution, i.e. , then, using the low rank approximation of the posterior covariance, we compute a sample as
This tutorial shows:
- description of the inverse problem (the forward problem, the prior, and the misfit functional)
- convergence of the inexact Newton-CG algorithm
- low-rank-based approximation of the posterior covariance (built on a low-rank approximation of the Hessian of the data misfit)
- how to construct the low-rank approximation of the Hessian of the data misfit
- how to apply the inverse and square-root inverse Hessian to a vector efficiently
- samples from the Gaussian approximation of the posterior
Goals:
By the end of this notebook, you should be able to:
- understand the Bayesian inverse framework
- visualise and understand the results
- modify the problem and code
Mathematical tools used:
- Finite element method
- Derivation of gradiant and Hessian via the adjoint method
- inexact Newton-CG
- Armijo line search
- Bayes' formula
- randomized eigensolvers
List of software used:
- FEniCS, a parallel finite element element library for the discretization of partial differential equations
- PETSc, for scalable and efficient linear algebra operations and solvers
- Matplotlib, A great python package that I used for plotting many of the results
- Numpy, A python package for linear algebra. While extensive, this is mostly used to compute means and sums in this notebook.
1. Load modules
from __future__ import absolute_import, division, print_function
import dolfin as dl
import math
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import sys
import os
sys.path.append( os.environ.get('HIPPYLIB_BASE_DIR', "../") )
from hippylib import *
import nb
import logging
logging.getLogger('FFC').setLevel(logging.WARNING)
logging.getLogger('UFL').setLevel(logging.WARNING)
dl.set_log_active(False)
np.random.seed(seed=1)
2. Generate the true parameter
This function generates a random field with a prescribed anysotropic covariance function.
def true_model(Vh, gamma, delta, anis_diff):
prior = BiLaplacianPrior(Vh, gamma, delta, anis_diff )
noise = dl.Vector()
prior.init_vector(noise,"noise")
noise_size = get_local_size(noise)
noise.set_local( np.random.randn( noise_size ) )
atrue = dl.Vector()
prior.init_vector(atrue, 0)
prior.sample(noise,atrue)
return atrue
3. Set up the mesh and finite element spaces
We compute a two dimensional mesh of a unit square with nx by ny elements. We define a P2 finite element space for the state and adjoint variable and P1 for the parameter.
ndim = 2
nx = 64
ny = 64
mesh = dl.UnitSquareMesh(nx, ny)
Vh2 = dl.FunctionSpace(mesh, 'Lagrange', 2)
Vh1 = dl.FunctionSpace(mesh, 'Lagrange', 1)
Vh = [Vh2, Vh1, Vh2]
print("Number of dofs: STATE={0}, PARAMETER={1}, ADJOINT={2}".format(
Vh[STATE].dim(), Vh[PARAMETER].dim(), Vh[ADJOINT].dim()) )
Number of dofs: STATE=16641, PARAMETER=4225, ADJOINT=16641
4. Set up the forward problem
To set up the forward problem we use the PDEVariationalProblem class, which requires the following inputs
- the finite element spaces for the state, parameter, and adjoint variables Vh
- the pde in weak form pde_varf
- the boundary conditions bc for the forward problem and bc0 for the adjoint and incremental problems.
The PDEVariationalProblem class offer the following functionality:
- solving the forward/adjoint and incremental problems
- evaluate first and second partial derivative of the forward problem with respect to the state, parameter, and adojnt variables.
def u_boundary(x, on_boundary):
return on_boundary and ( x[1] < dl.DOLFIN_EPS or x[1] > 1.0 - dl.DOLFIN_EPS)
u_bdr = dl.Expression("x[1]", degree=1)
u_bdr0 = dl.Constant(0.0)
bc = dl.DirichletBC(Vh[STATE], u_bdr, u_boundary)
bc0 = dl.DirichletBC(Vh[STATE], u_bdr0, u_boundary)
f = dl.Constant(0.0)
def pde_varf(u,a,p):
return dl.exp(a)*dl.inner(dl.nabla_grad(u), dl.nabla_grad(p))*dl.dx - f*p*dl.dx
pde = PDEVariationalProblem(Vh, pde_varf, bc, bc0, is_fwd_linear=True)
4. Set up the prior
To obtain the synthetic true paramter we generate a realization of a Gaussian random field with zero average and covariance matrix , where is a differential operator of the form Here is an s.p.d. anisotropic tensor of the form
For the prior model, we assume that we can measure the log-permeability coefficient at locations, and we denote with , , such measures. We also introduce the mollifier functions and we let where is a penalization costant (10 for this problem) and .
We then compute , the mean of the prior measure, as a regularized least-squares fit of these point observations by solving
Finally the prior distribution is , with .
gamma = .1
delta = .5
anis_diff = dl.Expression(code_AnisTensor2D, degree=1)
anis_diff.theta0 = 2.
anis_diff.theta1 = .5
anis_diff.alpha = math.pi/4
atrue = true_model(Vh[PARAMETER], gamma, delta,anis_diff)
locations = np.array([[0.1, 0.1], [0.1, 0.9], [.5,.5], [.9, .1], [.9, .9]])
pen = 1e1
prior = MollifiedBiLaplacianPrior(Vh[PARAMETER], gamma, delta, locations, atrue, anis_diff, pen)
print("Prior regularization: (delta_x - gamma*Laplacian)^order: delta={0}, gamma={1}, order={2}".format(
delta, gamma,2) )
objs = [dl.Function(Vh[PARAMETER],atrue), dl.Function(Vh[PARAMETER],prior.mean)]
mytitles = ["True Parameter", "Prior mean"]
nb.multi1_plot(objs, mytitles)
plt.show()
model = Model(pde,prior, misfit)
Prior regularization: (delta_x - gamma*Laplacian)^order: delta=0.5, gamma=0.1, order=2
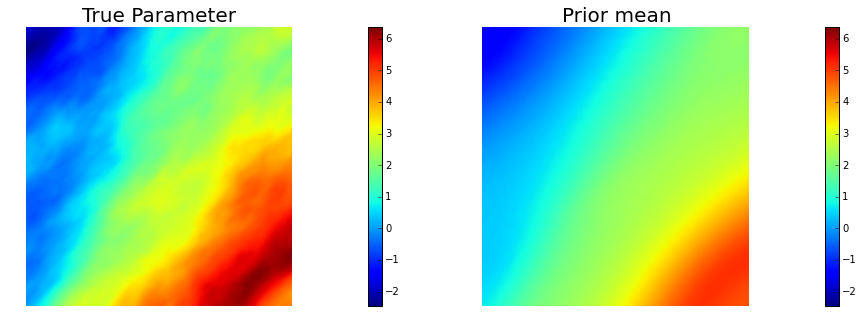
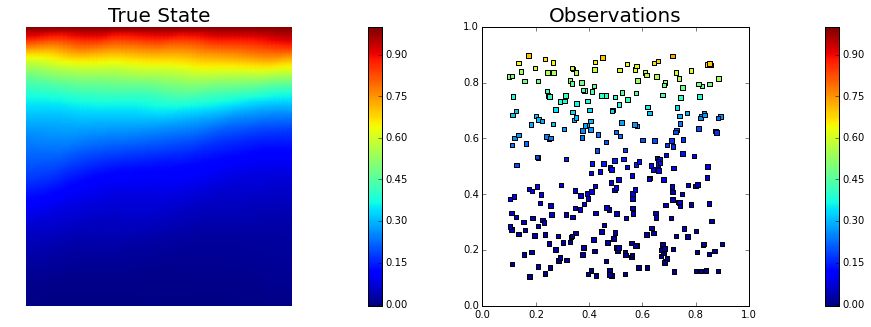
5. Set up the misfit functional and generate synthetic observations
To setup the observation operator, we generate ntargets random locations where to evaluate the value of the state.
To generate the synthetic observation, we first solve the forward problem using the true parameter . Synthetic observations are obtained by perturbing the state variable at the observation points with a random gaussian noise. rel_noise is the signal to noise ratio.
ntargets = 300
rel_noise = 0.01
targets = np.random.uniform(0.1,0.9, [ntargets, ndim] )
print("Number of observation points: {0}".format(ntargets))
misfit = PointwiseStateObservation(Vh[STATE], targets)
utrue = pde.generate_state()
x = [utrue, atrue, None]
pde.solveFwd(x[STATE], x, 1e-9)
misfit.B.mult(x[STATE], misfit.d)
MAX = misfit.d.norm("linf")
noise_std_dev = rel_noise * MAX
randn_perturb(misfit.d, noise_std_dev)
misfit.noise_variance = noise_std_dev*noise_std_dev
vmax = max( utrue.max(), misfit.d.max() )
vmin = min( utrue.min(), misfit.d.min() )
plt.figure(figsize=(15,5))
nb.plot(dl.Function(Vh[STATE], utrue), mytitle="True State", subplot_loc=121, vmin=vmin, vmax=vmax)
nb.plot_pts(targets, misfit.d, mytitle="Observations", subplot_loc=122, vmin=vmin, vmax=vmax)
plt.show()
Number of observation points: 300
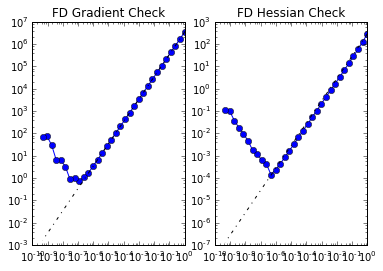
6. Set up the model and test gradient and Hessian
The model is defined by three component:
- the PDEVariationalProblem pde which provides methods for the solution of the forward problem, adjoint problem, and incremental forward and adjoint problems.
- the Prior prior which provides methods to apply the regularization (precision) operator to a vector or to apply the prior covariance operator (i.e. to solve linear system with the regularization operator)
- the Misfit misfit which provides methods to compute the cost functional and its partial derivatives with respect to the state and parameter variables.
To test gradient and the Hessian of the model we use forward finite differences.
model = Model(pde, prior, misfit)
a0 = dl.interpolate(dl.Expression("sin(x[0])", degree=5), Vh[PARAMETER])
modelVerify(model, a0.vector(), 1e-12)
(yy, H xx) - (xx, H yy) = 7.57910091653e-15
7. Compute the MAP point
We used the globalized Newtown-CG method to compute the MAP point.
a0 = prior.mean.copy()
solver = ReducedSpaceNewtonCG(model)
solver.parameters["rel_tolerance"] = 1e-9
solver.parameters["abs_tolerance"] = 1e-12
solver.parameters["max_iter"] = 25
solver.parameters["inner_rel_tolerance"] = 1e-15
solver.parameters["c_armijo"] = 1e-4
solver.parameters["GN_iter"] = 5
x = solver.solve(a0)
if solver.converged:
print("\nConverged in ", solver.it, " iterations.")
else:
print("\nNot Converged")
print("Termination reason: ", solver.termination_reasons[solver.reason])
print("Final gradient norm: ", solver.final_grad_norm)
print("Final cost: ", solver.final_cost)
plt.figure(figsize=(15,5))
nb.plot(dl.Function(Vh[STATE], x[STATE]), subplot_loc=121,mytitle="State")
nb.plot(dl.Function(Vh[PARAMETER], x[PARAMETER]), subplot_loc=122,mytitle="Parameter")
plt.show()
It cg_it cost misfit reg (g,da) ||g||L2 alpha tolcg
1 1 1.206547e+03 1.206233e+03 3.147385e-01 -1.570552e+04 1.042537e+05 1.000000e+00 5.000000e-01
2 3 3.459350e+02 3.446814e+02 1.253641e+00 -1.846772e+03 1.431429e+04 1.000000e+00 3.705435e-01
3 1 2.746765e+02 2.733672e+02 1.309257e+00 -1.424615e+02 1.003736e+04 1.000000e+00 3.102873e-01
4 7 1.691763e+02 1.647605e+02 4.415777e+00 -2.128491e+02 3.871034e+03 1.000000e+00 1.926938e-01
5 6 1.573210e+02 1.522926e+02 5.028367e+00 -2.345647e+01 1.821115e+03 1.000000e+00 1.321670e-01
6 14 1.424926e+02 1.297495e+02 1.274310e+01 -2.988285e+01 1.157426e+03 1.000000e+00 1.053661e-01
7 2 1.421601e+02 1.294134e+02 1.274672e+01 -6.643211e-01 7.325602e+02 1.000000e+00 8.382545e-02
8 22 1.407914e+02 1.253200e+02 1.547141e+01 -2.734442e+00 4.409802e+02 1.000000e+00 6.503749e-02
9 14 1.407826e+02 1.253781e+02 1.540453e+01 -1.744746e-02 5.057992e+01 1.000000e+00 2.202639e-02
10 29 1.407817e+02 1.253307e+02 1.545107e+01 -1.819642e-03 1.502434e+01 1.000000e+00 1.200472e-02
11 38 1.407817e+02 1.253304e+02 1.545139e+01 -2.502663e-07 1.390539e-01 1.000000e+00 1.154904e-03
12 54 1.407817e+02 1.253303e+02 1.545139e+01 -1.380451e-12 2.625467e-04 1.000000e+00 5.018311e-05
Converged in 12 iterations.
Termination reason: Norm of the gradient less than tolerance
Final gradient norm: 5.41022518768e-09
Final cost: 140.781736843
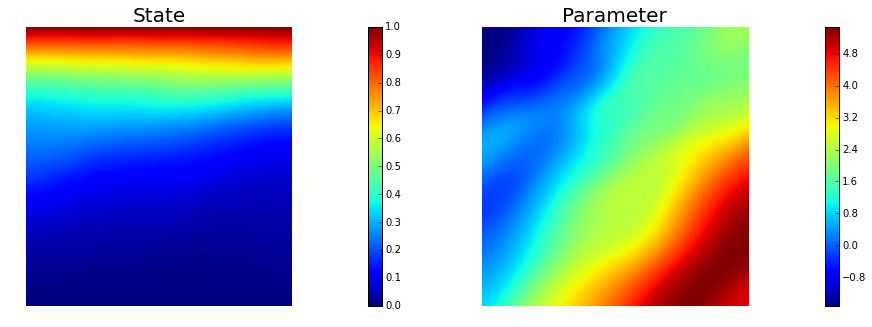
8. Compute the low rank Gaussian approximation of the posterior
We used the double pass algorithm to compute a low-rank decomposition of the Hessian Misfit. In particular, we solve
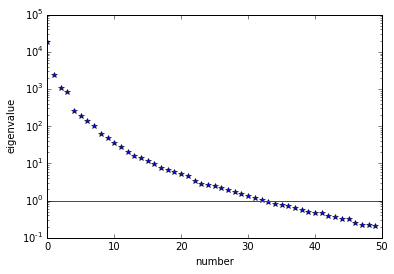
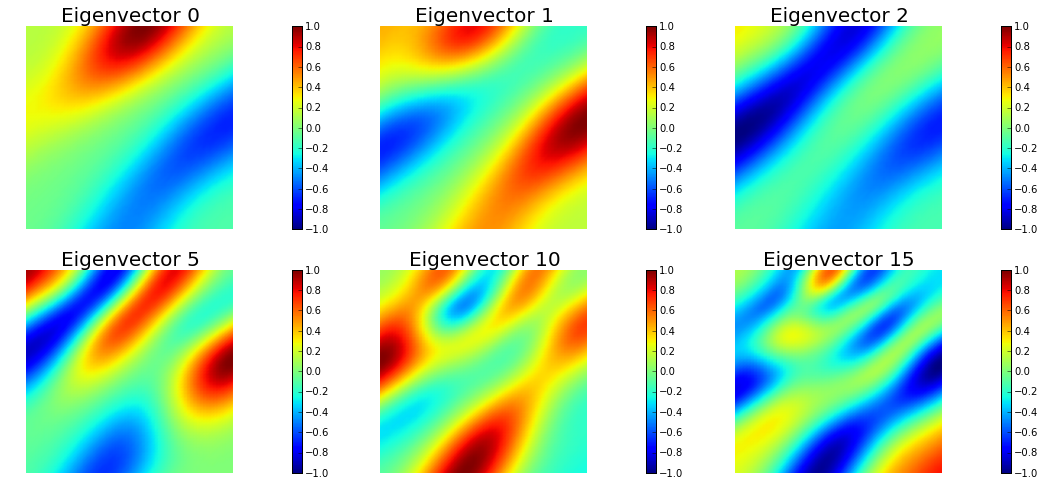
The Figure shows the largest k generalized eigenvectors of the Hessian misfit. The effective rank of the Hessian misfit is the number of eigenvalues above the red line (y=1). The effective rank is independent of the mesh size.
model.setPointForHessianEvaluations(x)
Hmisfit = ReducedHessian(model, solver.parameters["inner_rel_tolerance"], gauss_newton_approx=False, misfit_only=True)
k = 50
p = 20
print("Single/Double Pass Algorithm. Requested eigenvectors: {0}; Oversampling {1}.".format(k,p))
Omega = np.random.randn(get_local_size(x[PARAMETER]), k+p)
d, U = doublePassG(Hmisfit, prior.R, prior.Rsolver, Omega, k)
posterior = GaussianLRPosterior(prior, d, U)
posterior.mean = x[PARAMETER]
plt.plot(range(0,k), d, 'b*', range(0,k+1), np.ones(k+1), '-r')
plt.yscale('log')
plt.xlabel('number')
plt.ylabel('eigenvalue')
nb.plot_eigenvectors(Vh[PARAMETER], U, mytitle="Eigenvector", which=[0,1,2,5,10,15])
Single/Double Pass Algorithm. Requested eigenvectors: 50; Oversampling 20.
9. Prior and posterior pointwise variance fields
compute_trace = True
if compute_trace:
post_tr, prior_tr, corr_tr = posterior.trace(method="Randomized", r=200)
print("Posterior trace {0:5e}; Prior trace {1:5e}; Correction trace {2:5e}".format(post_tr, prior_tr, corr_tr))
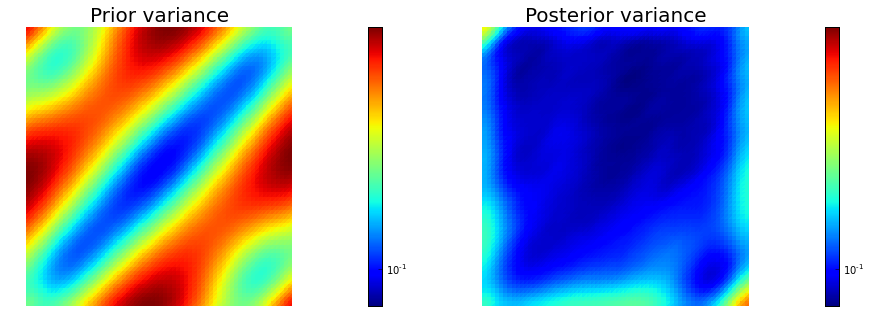
post_pw_variance, pr_pw_variance, corr_pw_variance = posterior.pointwise_variance(method="Randomized", r=200)
objs = [dl.Function(Vh[PARAMETER], pr_pw_variance),
dl.Function(Vh[PARAMETER], post_pw_variance)]
mytitles = ["Prior variance", "Posterior variance"]
nb.multi1_plot(objs, mytitles, logscale=True)
plt.show()
Posterior trace 1.058859e-01; Prior trace 3.949847e-01; Correction trace 2.890987e-01
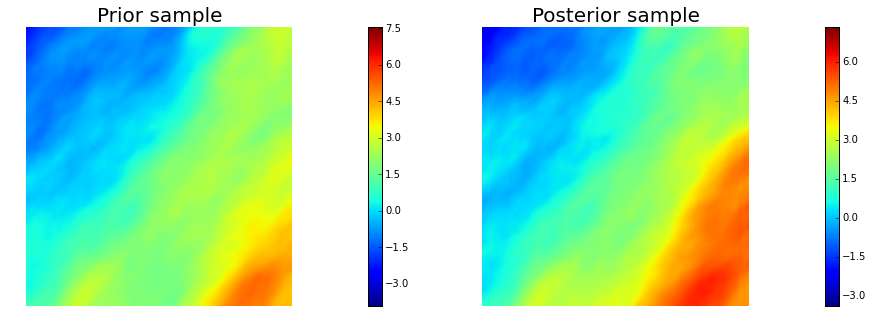
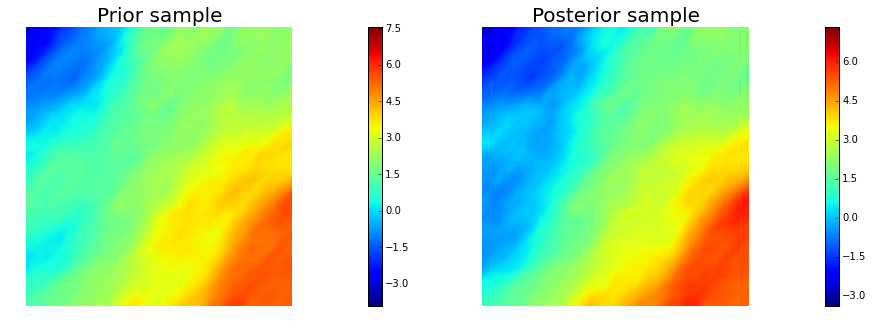
10. Generate samples from Prior and Posterior
nsamples = 5
noise = dl.Vector()
posterior.init_vector(noise,"noise")
noise_size = get_local_size(noise)
s_prior = dl.Function(Vh[PARAMETER], name="sample_prior")
s_post = dl.Function(Vh[PARAMETER], name="sample_post")
pr_max = 2.5*math.sqrt( pr_pw_variance.max() ) + prior.mean.max()
pr_min = -2.5*math.sqrt( pr_pw_variance.max() ) + prior.mean.min()
ps_max = 2.5*math.sqrt( post_pw_variance.max() ) + posterior.mean.max()
ps_min = -2.5*math.sqrt( post_pw_variance.max() ) + posterior.mean.min()
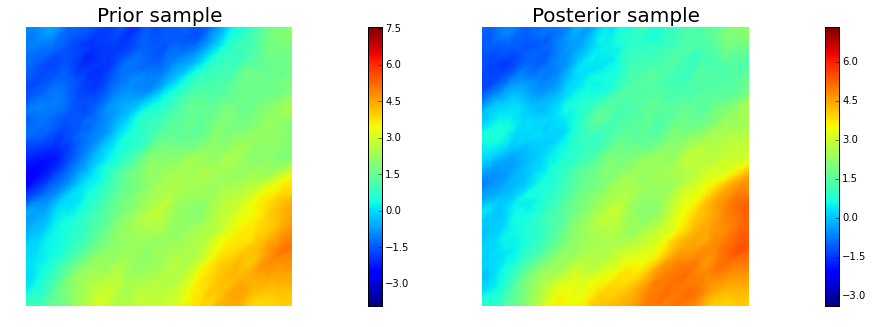
for i in range(nsamples):
noise.set_local( np.random.randn( noise_size ) )
posterior.sample(noise, s_prior.vector(), s_post.vector())
plt.figure(figsize=(15,5))
nb.plot(s_prior, subplot_loc=121, mytitle="Prior sample", vmin=pr_min, vmax=pr_max)
nb.plot(s_post, subplot_loc=122, mytitle="Posterior sample", vmin=ps_min, vmax=ps_max)
plt.show()
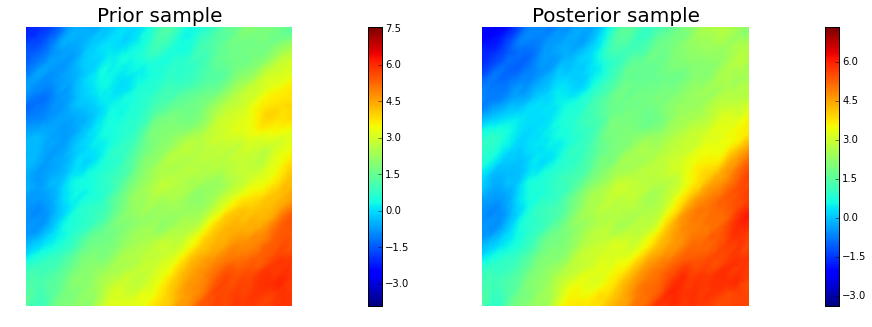
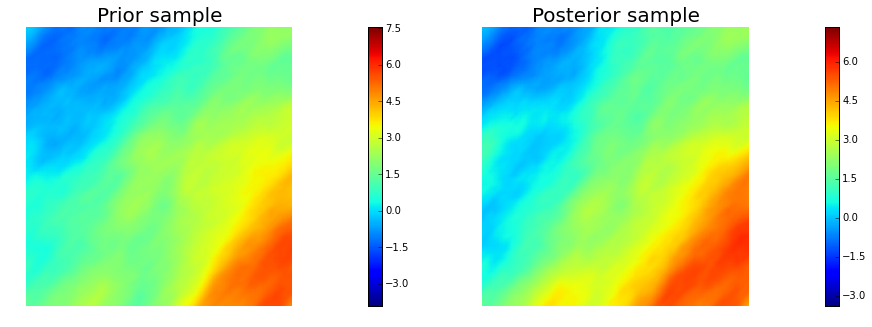
Copyright (c) 2016-2018, The University of Texas at Austin & University of California, Merced. All Rights reserved. See file COPYRIGHT for details.
This file is part of the hIPPYlib library. For more information and source code availability see https://hippylib.github.io.
hIPPYlib is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License (as published by the Free Software Foundation) version 2.0 dated June 1991.